
At Adamo, we built our teleop stack around a simple belief: latency is the single biggest bottleneck in robotics teleoperation today. Not video quality. Not UI. Latency.
Move a joystick, wait 200ms, watch the robot respond. That gap might sound small, but a robot arm moving at 1 m/s covers 20cm in that time. Enough to miss a pick, clip an obstacle, or force an operator into slow, cautious movements that kill throughput.
Most teleop platforms sit between 150-400ms glass-to-glass, the time from a camera capturing a frame on the robot to that frame hitting the operator's screen. Adamo runs under 40ms. Not in a demo. Over the public internet, across real deployments.
The short version: we threw out WebRTC and built a transport layer purpose-built for robot teleoperation. Here's the longer version.
Why We Ditched WebRTC
WebRTC is solid technology. It solved real-time video between browsers and powers every major video calling platform. When robotics companies need to stream from a robot to a screen, it's the obvious first reach.
We reached for it too. Then we benchmarked it.
The codecs are fine. The problem is the architecture around them is designed for conversations between people, where 100-200ms of delay is imperceptible.
Connection setup is slow. ICE candidates, STUN/TURN negotiation, offer-answer exchanges. Best case, seconds before a frame moves. Worst case on a flaky warehouse network, 10-15 seconds. When an operator needs to intervene on a robot heading toward a shelf, that's not acceptable.
Jitter buffers add hidden delay. WebRTC smooths playback by holding frames. Great for calls where nobody notices an extra 40ms. For teleop, that's 40ms of the operator reacting to where the robot was, not where it is.
Congestion control prioritises the wrong thing. WebRTC protects picture quality, it'll retransmit and buffer rather than skip to the latest frame. In a phone call, you want every frame. In teleoperation, you want the most recent frame, immediately, even if a few got dropped along the way.
These aren't bugs. They're design choices that make perfect sense for video calls and actively hurt teleoperation. So we built something else.
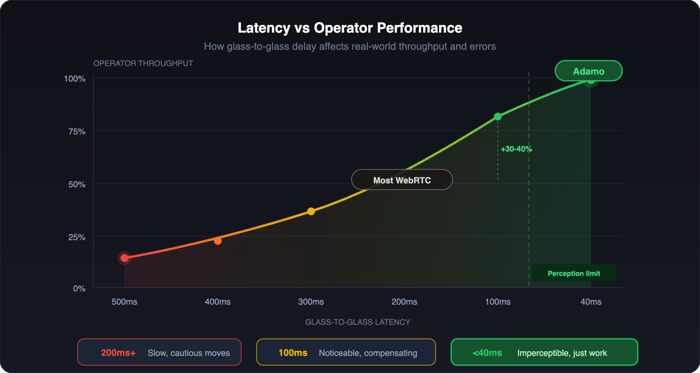 Operator throughput is vastly superior with Adamo versus WebRTC
Operator throughput is vastly superior with Adamo versus WebRTCWhat We Built Instead
Our stack optimises for one thing: the shortest possible path between a robot's camera and an operator's eyes.
No batching. Most network stacks combine small messages for efficiency. We don't. Frames ship the instant they're encoded, one at a time.
Drop, don't buffer. If a frame arrives late, we throw it away and show the next one. A 30ms-old frame is useful. A 200ms-old frame the system queued while "catching up" is dangerous.
Hardware encoding everywhere. Software encoding on a robot's CPU adds too much time. Our stack auto-selects the fastest hardware encoder available, Jetson, desktop GPU, whatever the robot has. Raw camera frame to H.264 in under 5ms.
Frame-by-frame bitrate adaptation. Network conditions between a warehouse and a remote operator change constantly. Our congestion control adjusts bitrate every frame, not every few seconds. Bandwidth drops, quality drops that frame. Bandwidth recovers, we ramp back up immediately. No buffering and hoping.
The Numbers
Typical deployment, robot in a warehouse, operator in another city, standard internet on both ends:
- Encode: 3-5ms (hardware H.264)
- Network transit: 15-25ms (geography-dependent)
- Decode + render: 5-8ms
- Glass-to-glass total: 25-38ms
That's local USB camera territory. The robot feels like it's in the room.
For comparison, WebRTC-based teleop platforms in the same conditions measure 150-400ms, with spikes above 500ms when the jitter buffer fills.
What Changes at 40ms
Low latency doesn't just make teleoperation feel nicer. It changes what's possible.
At 200ms, operators work slowly and carefully. Every movement compensates for the delay. Reactive tasks, catching something that's falling, adjusting to an unexpected obstacle, fine manipulation, aren't realistic. Fatigue is high because the cognitive load of mentally predicting where the robot actually is never stops.
Below 40ms, the delay drops under the threshold of human perception. Operators stop thinking about latency and focus on the task. They move faster, make fewer errors, and can handle situations that are flat-out impossible at higher delays.
Across our deployments, cutting latency from 150ms to sub-40ms has increased operator throughput by 30-40%, with error rates roughly halving. Same operators. Better tool.
Try It
If your teleoperation latency starts with a number bigger than 5, we should talk. Learn more about the stack at https://adamohq.com or reach out to James@adamohq.com to learn more!


